In the era of smart devices, voice assistants like Siri, Alexa, and Google Assistant have become integral parts of our daily lives. These assistants help us accomplish various tasks, from setting reminders to controlling home devices. In this blog, we will dive into how you can create your own custom voice assistant using Python and machine learning techniques. We'll explore the basic principles of speech recognition, NLP (Natural Language Processing), and text-to-speech (TTS) systems to build a functional voice assistant.
1. Introduction to Voice Assistants
Voice assistants are AI-powered systems that process and respond to voice commands. They use speech recognition to understand spoken language, NLP for command processing, and TTS to generate responses. The seamless integration of these technologies allows the assistant to interact with users conversationally.
2. Core Technologies
There are three key components in building a voice assistant:
Speech Recognition: Converts spoken language into text.
NLP (Natural Language Processing): Analyzes the text input and extracts meaning to understand the user's intent.
Text-to-Speech (TTS): Converts text into spoken language to deliver responses.
3. Building Blocks of a Voice Assistant
To create a simple voice assistant, you will need:
Python: The programming language we'll use for building our assistant.
SpeechRecognition: A library for speech-to-text.
Google Text-to-Speech (gTTS) or pyttsx3: For TTS functionality.
NLTK or spaCy: For NLP processing.
Machine Learning: Optionally, to train the assistant to handle more complex tasks.
4. Step-by-Step Guide to Building a Voice Assistant
Step 1: Installing Required Libraries
Start by installing the necessary libraries:
pip install SpeechRecognition
pip install pyttsx3
pip install nltk
pip install pyaudio
pip install py3-tts
pip install objc
Step 2: Capturing Voice Commands
To recognize voice commands, we will use the speech_recognition library to capture audio input and convert it into text.
import speech_recognition as sr
def listen_command():
recognizer = sr.Recognizer()
with sr.Microphone() as source:
print("Listening...")
audio = recognizer.listen(source)
try:
command = recognizer.recognize_google(audio)
print(f"User said: {command}")
except sr.UnknownValueError:
print("Sorry, I didn't catch that.")
command = None
return command
listen_command()

Step 3: Understanding the Commands
To make the assistant understand commands, we will use basic NLP to analyze the text and identify key intents.
import nltk
from nltk.tokenize import word_tokenize
def process_command(command):
tokens = word_tokenize(command.lower())
if 'time' in tokens:
return "tell_time"
elif 'date' in tokens:
return "tell_date"
elif 'weather' in tokens:
return "check_weather"
else:
return "unknown_command"
Step 4: Responding to Commands
Once the intent is identified, the assistant will perform the appropriate action. For this, we will use pyttsx3 for TTS to respond with voice output.
import pyttsx3
import time
from datetime import datetime
def respond_to_command(intent):
engine = pyttsx3.init()
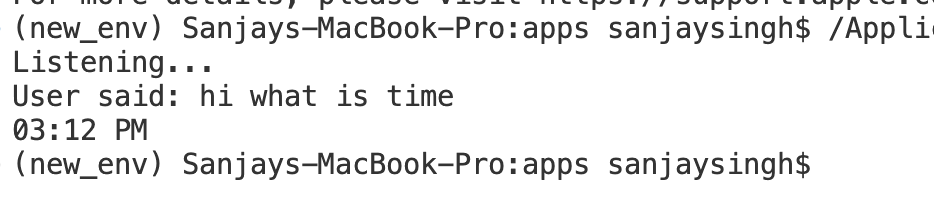
if intent == "tell_time":
response = time.strftime("%I:%M %p")
elif intent == "tell_date":
response = datetime.now().strftime("%B %d, %Y")
else:
response = "Sorry, I can't understand that command."
engine.say(response)
engine.runAndWait()
command = listen_command()
if command:
intent = process_command(command)
respond_to_command(intent)
Full code:
import speech_recognition as sr
import nltk
from nltk.tokenize import word_tokenize
import pyttsx3
from datetime import datetime
import time
def listen_command():
recognizer = sr.Recognizer()
with sr.Microphone() as source:
print("Listening...")
audio = recognizer.listen(source)
try:
command = recognizer.recognize_google(audio)
print(f"User said: {command}")
except sr.UnknownValueError:
print("Sorry, I didn't catch that.")
command = None
return command
def process_command(command):
tokens = word_tokenize(command.lower())
if 'time' in tokens:
return "tell_time", None
elif 'date' in tokens:
return "tell_date", None
elif 'weather' in tokens:
city_name = extract_city_name(command)
return "check_weather", city_name
else:
return "unknown_command", None
def respond_to_command(intent):
engine = pyttsx3.init()
if intent == "tell_time":
response = time.strftime("%I:%M %p")
print(response)
elif intent == "tell_date":
response = datetime.now().strftime("%B %d, %Y")
print(response)
else:
response = "Sorry, I can't understand that command."
engine.say(response)
engine.runAndWait()
command = listen_command()
if command:
intent = process_command(command)
respond_to_command(intent)
5. Advanced Features
Adding Machine Learning Capabilities
You can extend the assistant by incorporating machine learning models to handle more complex tasks. For example, you could use classifiers to detect specific patterns or intents in commands and improve the assistant's intelligence using pre-trained NLP models like BERT or GPT.
Integration with APIs
You can also connect the assistant with external APIs like OpenWeatherMap for weather updates, or Google Calendar for setting reminders.
import requests
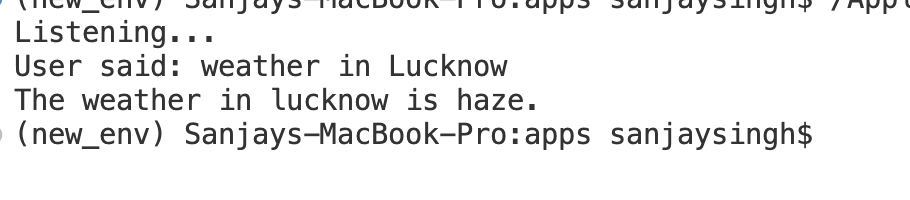
def get_weather(city_name):
api_key = "your api key"
url = f"http://api.openweathermap.org/data/2.5/weather?q={city_name}&appid={api_key}"
response = requests.get(url)
weather_data = response.json()
if weather_data.get('cod') != 200:
return f"Sorry, I couldn't fetch the weather for {city_name}. Please try again."
return f"The weather in {city_name} is {weather_data['weather'][0]['description']}."
Conclusion
With Python and basic machine learning principles, creating a custom voice assistant is achievable for developers at any skill level. As demonstrated, integrating speech recognition, NLP, and TTS allows you to build an interactive system that can understand and respond to commands. You can further enhance the assistant with machine learning models, API integrations, and advanced NLP techniques to create a powerful and intelligent assistant that suits your needs.







